[toc]
DQL 语句
连结表
连结
连结对应的语句为 JOIN。
为了减少内存浪费、方便更新数据、且维护数据的一致性,在设计关系表时,把信息分解成多个表。
如果某一列在其中一个表中为主键 (primary key),并且同样的列也被存储在另外一张表中,用来关联两张表,那么这列在另外一张表中叫做外键。
外键 (foreign key)
外键为某个表中的某一列,包含另一个表中的主键值,定义了两个表之间的关系。
类型
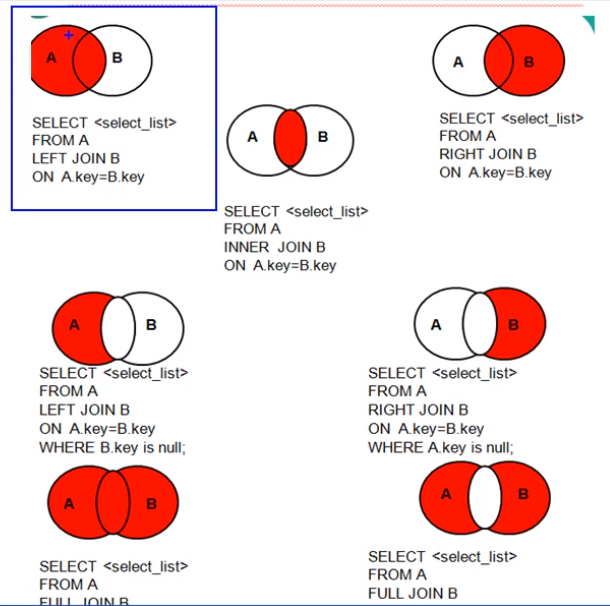
- 内联结(等值连结)
基于行的等值匹配,将一个表中的一行与另一个表中的行连结。 - 外部连结
除了关联行,还包含没有关联行的那些行。关键字OUTER JOIN,通过LEFT和RIGHT关键字指定包括其所有行的表。
查询结果为主表中的所有的记录,如果从表有匹配项,则显示匹配项;如果从表没有匹配项,则显示NULL。
应用场景:一般用于查询主表中有,但是从表没有的记录。
特点:- 外联结分主从表,两表顺序不能任意调换
- 左连接,左表为主表;有链接,右表为主表
- 全外联结
既有左连接又有右连接。两张表的所有记录都会返回,没有匹配的都为 NULL。 - 自然连结
不常用。 - 自联结

子查询
当一个查询语句中又嵌套了另一个完整的 SELECT 语句,则被嵌套的 SELECT 语句成为子查询或内查询,外面的 SELECT 语句称为主查询或外查询。
按照子查询出现的位置进行分类:
- SELECT 后
要求:子查询结果为单行单列(标量子查询) - FROM 后
要求:子查询的结果可以为多行多列(无要求) - WHERE 或 HAVING 后
要求:子查询结果必须为单列,单行/多行子查询 - EXIST 后面
要求:子查询结果或必须为单列(相关子查询)
特点
- 子查询放在条件中,必须放在条件的右侧
- 子查询一般放在小括号中
- 子查询的执行优先于主查询
- 单行子查询对应了单行操作符:
< > >= <= = <> - 多行子查询对应了多行操作符:
ANY/SOME ALL IN
多行子查询
IN:判断某字段是否在指定列表内ANY/SOME:判断某字段的值是否满足其中任意一个ALL:判断某字段的值是否满足里面所有的
分页查询
应用场景
当页面上的数据,一页显示不全,需要分页显示。
分页查询的 SQL 命令请求数据库服务器->服务器响应查询到的多条数据->前台页面
语法:
1 | SELECT # 7 |
特点
- 0-indexed,默认为0
- LIMIT 两个参数:起始索引,条目数
假设要显示的页数是 page,每页显示的条目数为 size
1 | SELECT * |
联合查询
当查询结果来自于多张表,但多张表之间没有关联,此时往往使用联合查询。
1 | SELECT FROM WHERE |
多条查询语句的查询列数必须一致。
列必须对应,虽然语法正确,但数据无意义。
UNION 自动去重,去除重复行。
UNION ALL 可以支持重复项。
小结

DDL 语言
数据定义语言,Data Define Language 数据定义语言,用于对数据库和表的管理和操作。
库的管理
1 | -- 创建数据库 |
表的管理
创建表
1 | CREATE TABLE name ( |
数据类型
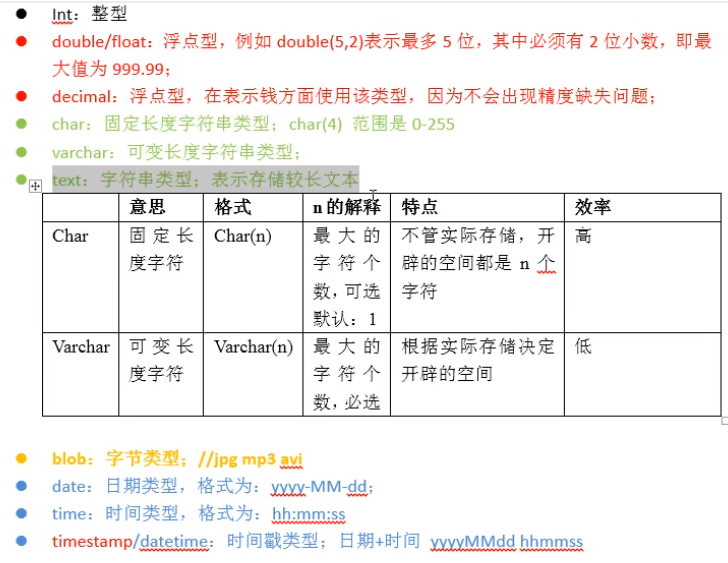
CHAR()固定字符长度,会用空格补齐,效率较高,在数据长度较为固定时使用,长度默认为 1;VARCHAR()可变字符长度,不会补齐;

1 | -- 整形 |
常见约束
用于限制表中字段数据的,从而进一步保证数据表中的数据是一致、准确、可靠的。
1 | NOT NULL # 非空,限制该字段为必填项 |
- 可多个字段作为一个组合主键,此时作为主键的多个字段不能同时重复
- 主表关联列和从表关联列的类型必须一致
- 主表的关联列要求必须是主键
支持列级约束:NOT NULL, DEFAULT, UNIQUE, PRIMARY KEY, CHECK
支持表级约束:UNIQUE, PRIMARY KEY, FOREIGN KEY
1 | CREATE TABLE stuinfo ( |
修改
1 | ALTER TABLE name |
删除表
1 | DROP TABLE IF EXISTS tbl_name; |
复制表
1 | CREATE TABLE newTable |
DML 语句
Data Manipulation Language 数据操纵语言
对表中的数据增删改。
插入数据
语法
1 | INSERT INTO tbl_name(field1, field2, ...) VALUES(val1, val2, ...); |
注意事项
- 字段和值列表一一对应,包含类型、约束等必须匹配
- 数值型的值,不用单引号,非数值型的值,必须使用单引号
- 字段顺序无要求
如何插入空字段:只要在 INSERT 时忽略这个字段即可。
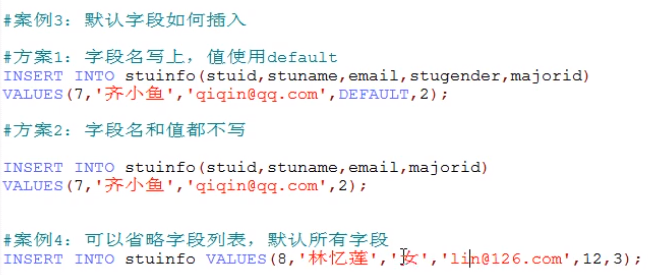
以上为插入单行,还可以批量插入
1 | INSERT INTO tbl_name(field1, field2, ...) |
自增长列
1 | CREATE TABLE gradeinfo ( |
如果自增主键不插入 NULL,则以插入数据为准。
要求
- 自增长列要求必须设置在一个键上,比如主键或唯一键
- 自增长列要求数据类型为数值型
- 一个表至多有一个自增长列
修改数据
1 | UPDATE stuinfo SET balance = balance - 5000 |
删除数据
DELETE 语句
1 | DELETE FROM name |
TRUNCATE 语句
1 | # 不支持 WHERE 语句 |
区别
DELETE可以添加WHERE条件,TRUNCATE不能添加WHERE条件,一次性清除所有数据。TRUNCATE删除旧表,建立新表。TRUNCATE效率较高。- 如果删除带自增长列的表,使用
DELETE删除后,重新插入数据,记录从断点处开始;TRUNCATE删除,重新插入,记录则从 1 重新开始。 DELETE删除数据,会返回受影响的行数;TRUNCATE删除数据,不会返回受影响行数。DELETE删除数据,可以支持事务回滚TRUNCATE删除数据,不支持事务回滚。
常用 DELETE。
事务
由单条 SQL 语句组成,要么全部成功,要么全部失败。
- 隐式事务,
INSERT, UPDATE, DELETE都属于隐式事务 - 显式事务,需要显式开启事务,需要先取消事务的自动提交
1 | SET AUTOCOMMIT = 0; |
三种现象
补充:数据丢失
两个或多个事务选择同一行,然后基于最初选定的值更新该行,一个事务更新的结果覆盖了另一个事务的更新。
脏读
对于两个事务T1, T2,T1读取了T2更新但还没有被提交的字段,之后,若T2回滚,T1读取的内容就是临时且无效的。
强调未提交的更新事务。
不可重复读
对于两个事务T1, T2,T1读取了一个字段,然后T2更新并提交了该字段,之后T1再次读取同一个字段,会读取到不同的值。
强调更新事务。
同一事务中两次对同一数据的读取结果不同。
幻读
对于两个事务T1, T2,T1从表中读取了一个字段,然后,T2在该表中插入了一些新的行,之后如果,T1再次读取同一个表,就会多出几行。
强调提交的插入或者删除事务。
MySQL 四种隔离级别
MySQL 默认隔离级别:REPEATABLE-READ 可重复读
1 | mysql> SELECT @@tx_isolation; |
READ UNCOMMITTED
读未提交,可能会发生脏读、不可重复读、以及幻读。
READ COMMITTED
其他事务无法读取未提交的修改(UPDATE)。
但是如果另外一个事务更新并提交,那么正在进行中的事务可能会前后读取到不同的数据。
解决了脏读。
REPEATABLE READ
可重复读,对于同一个事务来说,对同一个数据进行多次查询得到的结果相同。
解决脏读、不可重复读。
在一个事务中,对于相同数据的两次读取,在两次读取之间有其他事务插入并提交,导致未提交的事务读取到额外的数据,并有可能修改其他事务提交的数据。
SERIALIZABLE
可串行化。可解决以上三个问题。
在一个事务未提交时,另外一个事务进行插入、更新、删除操作时会被阻塞。
性能低,但是可以避免所有并发问题。
MySQL 设置隔离级别
每启动一个 MySQL 程序,就会获得一个单独的数据库连接,每个数据库连接都有一个全局变量 @@transaction_isolation,表示当前的事务隔离级别。
1 | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
回滚点 SAVEPOINT
1 | SET AUTOCOMMIT = 0; |
视图
含义:虚拟表,和普通表一样使用,MySQL 5.0.1 版本新特性,是通过表动态生成的数据。
把查询结果封装到一个临时结果集中。
只保存 SQL 逻辑,不保存数据。
应用场景
- 多个地方用到同样的查询结果
- 该查询结果使用的 SQL 较复杂
创建视图
假设我们要从 stuinfo 这张表中查询张姓学生的学生姓名以及专业
1 | SELECT stuname, majorname |
修改视图
1 | # 方式一 |
删除视图 & 查看视图
1 | DROP VIEW myv3; |
更新视图
插入
1
2
3
4
5
6
7
8
9# 首先新建视图
CREATE OR REPLACE VIEW myv1
AS
SELECT last_name, email
FROM employees;
# 插入,需要注意有些视图不允许插入
# 插入之后原始表被修改
INSERT INTO myv1 VALUES('FRANK', 'XXX@XX.COM');修改
1
2UPDATE myv1 SET last_name = 'frank'
WHERE last_nmame = 'FARNK';删除
1
2DELETE FROM myv1
WHERE last_name = 'frank';
上述更新视图操作很少使用。
不允许更新的视图
- 包含以下关键字的 SQL 语句:
分组函数、DISTINCT、GROUP BY、HAVING、UNION、UNION ALL
跟分组、联合查询相关的 - 常量视图
SELECT包含子查询- 连接表,虽然可更新但不可插入,统一理解为不能更新
- 嵌套了不能更新的视图
WHERE子句中的子查询引用了FROM子句的表
优点
- 实现了 SQL 语句的重用
- 简化复杂的 SQL 操作,封装细节
- 保护数据,提高安全性,因为用户不知道基表信息
变量
- 系统变量
- 全局变量
- 会话变量
- 自定义变量
- 用户变量
- 局部变量
系统变量
由系统提供,不是用户定义,属于服务器层面。
语法:
1 | SHOW VARIABLES; # 查看所有的系统变量 |
自定义变量
变量是用户自定义的。
使用步骤:
- 声明
- 赋值
- 使用(查看、比较、运算等)
用户变量
作用域:针对当前会话(连接)有效,同于会话变量的作用域。
可应用在任何地方。
1 | # 声明或初始化 |
局部变量
作用域仅仅在定义它的 begin end 中有效。
应用在 begin end 中的第一句。
- 声明
DACLARE 变量名 类型;DECLARE 变量名 类型 DEFAULT 值; - 赋值
SELECT 字段 INTO 局部变量名 FROM 表; - 使用
SELECT 局部变量名;
用户变量
1 | # 声明两个变量并赋初始值,求和,并打印 |
局部变量
1 | BEGIN |
存储过程和函数
类似于 C++ 函数。
好处:
- 提高代码重用性
- 简化操作
- 减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
存储过程
一组预先编译好的 SQL
语句的集合,理解成批处理语句。
创建
1 | CREATE PROCEDURE 存储过程名(args) |
调用
1 | CALL 存储过程名(实参列表); |
示例
以下 SQL 语句在客户端(DOS 窗口中运行)
无参存储过程
1 | DELIMITER $ |
带 IN 模式的存储过程
1 | CREATE PROCEDURE myp2 (IN beautyName VARCHAR(20)) |
带 OUT 模式的存储过程
1 | CREATE PROCEDURE myp5(IN beautyName VARCHAR(20), OUT boyName VARCHAR(20)) |
带 INOUT 模式的存储过程
1 | # 传入a和b两个值,最终a和b都翻倍并返回 |
删除存储过程
1 | DROP PROCEDURE 存储过程名; # 一次删除一条 |
查看存储过程的信息
1 | SHOW CREATE PROCEDURE 存储过程名; |
函数
与存储过程的区别在于有且仅有一个返回。
适合处理数据并返回结果。
而存储过程适合批量插入、批量更新。
创建
1 | CREATE FUNCTION func(args) RETURNS return_type |
调用
1 | # 返回公司的员工个数 |
查看函数
1 | SHOW CREATE FUNCTION func; |
删除函数
1 | DROP FUNCTION func; |
流程控制结构
- 顺序结构:程序从上往下依次执行
- 分支结构:程序从两条或多条路径中选择一条去执行
- 循环结构:程序在满足一定条件的基础上,重复执行一段代码
if 函数
1 | IF(cond, branch1, branch2); # 如果cond成立则执行branch1,否则执行branch2 |
case 结构
类似 C++ 的 switch 语句,一般用于实现等值判断
1
2
3
4
5CASE variable | expression | field_name
WHEN case1 THEN return_val1 | 语句1;
WHEN case2 THEN return_val2 | 语句2;
ELSE return_valn | 语句n;
END CASE;类似于 多重 if 语句,一般用于实现区间判断
1
2
3
4
5CASE
WHEN cond1 THEN ret_val1 | 语句1;
WHEN cond2 THEN ret_val2 | 语句2;
ELSE ret_valn | 语句n;
END CASE;
可以作为表达式嵌套在其它语句中使用,可以放在任何地方。
可以作为独立的语句使用,只能放在 BEGIN END 之间。
执行顺序:
- 满足条件,则执行对应语句然后结束
- 如果条件都不满足,则执行 ELSE 对应语句然后结束
- 如果 ELSE 省略且没有 CASE 被满足,那么返回 NULL
1 |
|
if 结构
1 | IF cond1 THEN 语句1; |
应用在 BEGIN END 中。
1 | CREATR FUNCTION test_if(score INT) RETURNS CHAR |
循环结构
WHILELOOPREPEAT
循环控制:
ITERATE,类似于continue,结束本次循环,继续下一次LEAVE,类似于break,跳出,结束当前循环
1 | # WHILE |
1 | # 插入指定次数次 |
循环结构小结
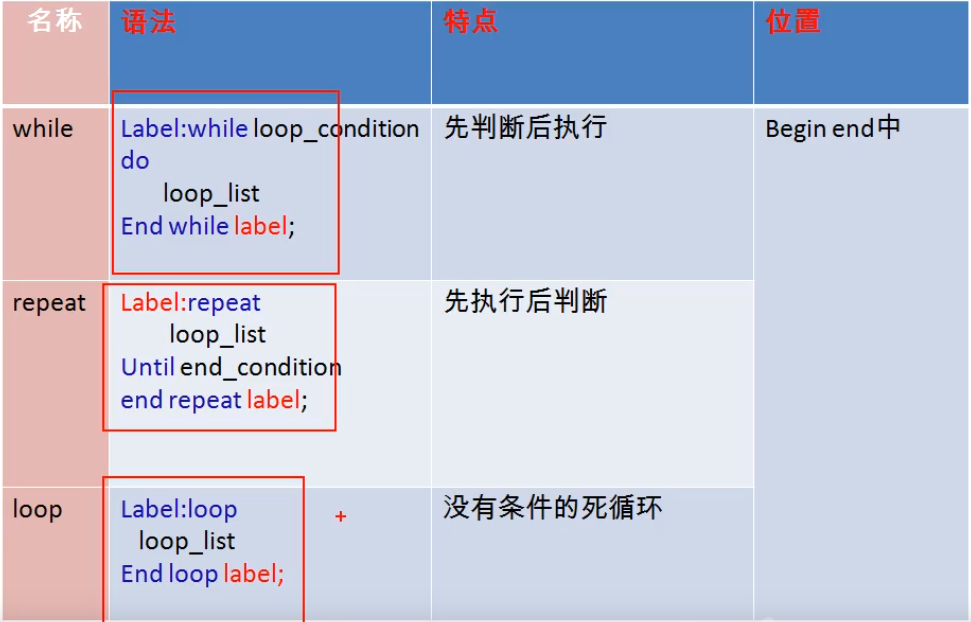
流程控制经典案例
已知表
stringContent,其中
字段id自增长content VARCHAR(20)
向该表插入指定个数的,随机的字符串1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23DROP TABLE IF EXISTS stringcontent;
CREATE TABLE stringcontent(
id INT PRIMARY KEY AUTO_INCREMENT,
content VARCHAR(20)
);
DELIMITER $
# 因为是批量插入,所以我们使用存储过程procedure
CREATE PROCEDURE insert_rand(IN num INT)
BEGIN
DECLARE i INT DEFAULT 1;
# DECLARE str VARCHAR(26) DEFAULT 'abcdefghijklmnopqrstuvwxyz';
ins: WHILE i <= num DO
SET i = i + 1; # 不要忘记更新循环变量
INSERT INTO stringcontent(content)
VALUES(substr(MD5(RAND()), 1, 20));
END WHILE ins;
END $
CALL insert_rand(20) $
SELECT * FROM stringcontent;tips:
RAND()生成[0, 1)之间的随机数,可以乘以某个数并加上偏移,再利用FLOOR()或者CEIL()来构造新的区间。
SQL 总结
系统变量
1 | SHOW [GLOBAL | SESSION] VARIABLES [LIKE 'XXX']; # 默认session |
- 全局变量
- 会话变量
自定义变量
用户变量
作用域:针对当前连接(会话)生效
位置:任意位置
使用:1
2
3
4
5
6
7
8# 声明并赋值 或 更新值
SET @var = val;
SET @var := val;
SELECT @var := val;
# 更新值
SELECT xx INTO @var FROM tbl;
# 使用
SELECT @var;局部变量
作用域:仅仅在定义它的代码块中有效
位置:只能放在代码块中,而且只能放在最前面(首先定义局部变量)1
2
3
4
5
6
7
8
9# 声明
DECLARE var type [default val];
# 赋值或更新
SET var = val;
SET var := val;
SELECT var := val;
SELECT xx INTO var FROM tbl;
#使用
SELECT var;
存储过程和函数
存储过程
说明:将一组完成特定功能的逻辑语句包装起来,对外暴露方法名
好处:
- 提高重用性
- 调用语句简单
- 减少了和数据库服务器连接的次数,提高效率
一、创建二、调用1
2
3
4
5
6# 参数模式:IN OUT INOUT,其中 IN 可以省略
# 存储过程体的每一条SQL语句都需要以分号结尾
CREATE PROCEDURE name(mode name type)
BEGIN
/*BODY*/
END $三、查看与删除1
2
3
4
5
6
7
8# 调用in模式参数
CALL name(args);
# 调用out模式参数
SET @arg;
CALL name(arg);
# 调用inout模式的参数
SET @arg = val;
CALL name(arg);1
2SHOW CREATE PROCEDURE name;
DROP PROCEDURE name;
函数
一、创建
1 | CREATE FUNCTION name(arg type) RETURNS type |
二、调用
1 | SELECT func(args); |
三、查看
1 | SHOW CREATE FUNCTION func; |
四、删除
1 | DROP FUNCTION func; |
流程控制结构
- 顺序结构
- 分支结构
- 循环结构
分支结构
IF结构1
2
3
4
5
6BEGIN
IF cond THEN branch1;
ELSEIF cond2 THEN branch2;
ELSE branch;
END IF;
END $只能放在代码块中。
CASE结构1
2
3
4
5
6
7BEGIN
CASE XXX
WHEN cond1 THEN branch1;
WHEN cond2 THEN branch2;
ELSE branch;
END CASE;
END $既可以在代码块内,也可以在代码块之外。
- 放在代码块之外,只能作为表达式,结合其他语句使用
- 放在代码块之内,则既可以作为表达式,也可以作为独立语句使用
需要在代码块中。
循环结构
WHILE1
2
3[tag:]WHILE cond DO
/*SOMETHING*/
END WHILE tag;
LOOP1
2
3[tag:]LOOP
/*SOMETHING*/
END LOOP tag;
REPEAT1
2
3
4[tag:]REPEAT
/*SOMETHING*/
UNTIL cond
END REPEAT tag;
对比:
- 三种循环都可以省略名称(tag),但如果循环中添加了循环控制语句
(LEAVE | ITERATE),则必须添加名称 LOOP一般用于实现简单的死循环WHILE先判断后执行REPEAT先执行后判断,无条件至少执行一次
循环控制语句
LEAVE,相当于break,用于跳出所在循环ITERATE,相当于continue,用于结束当此循环
一般搭配循环名称。